Summary of our findings on VideoLLMs' information flow.
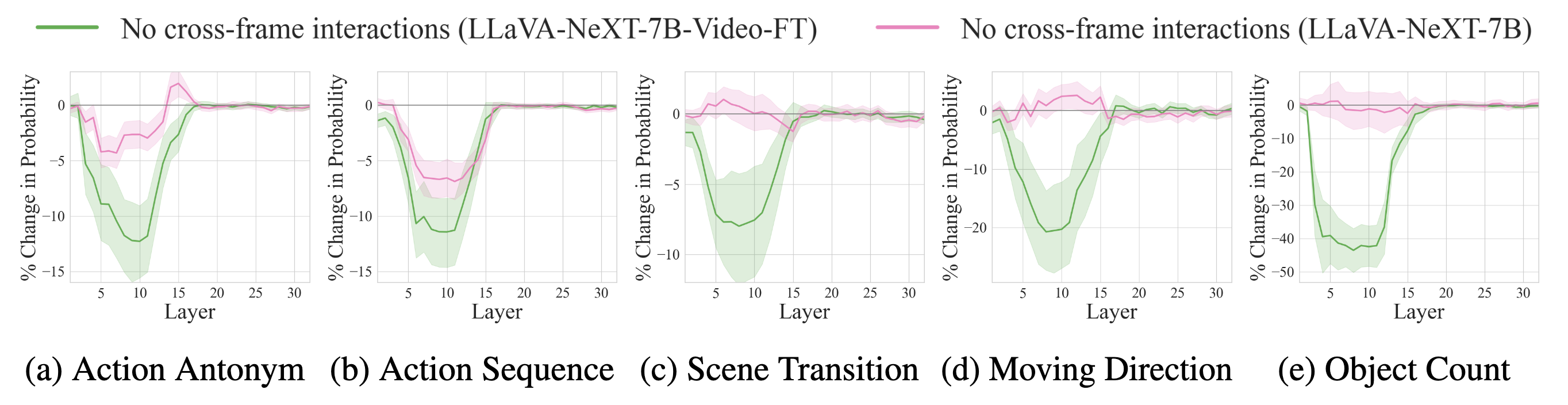
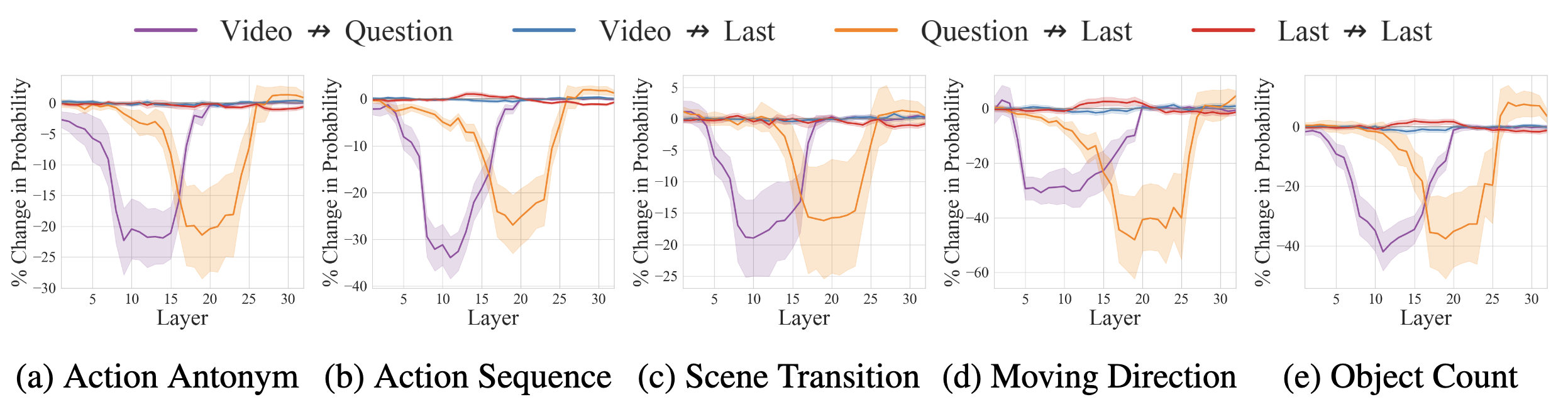
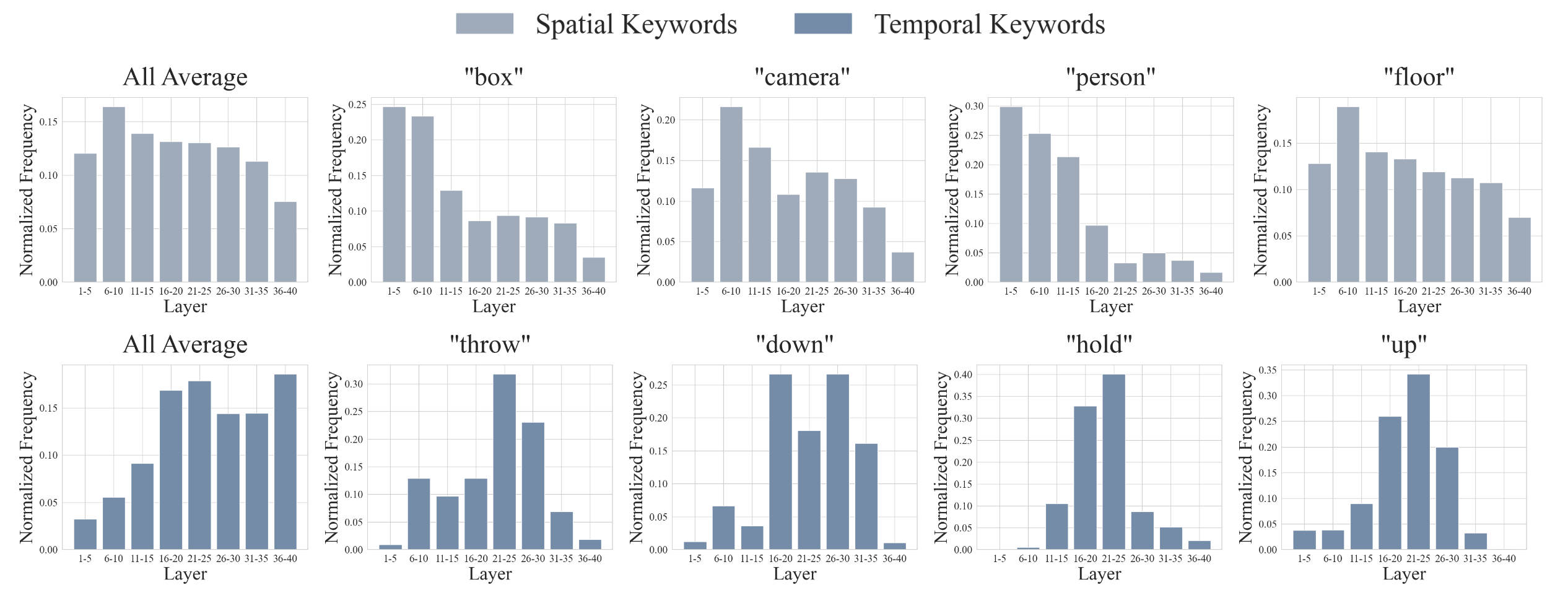
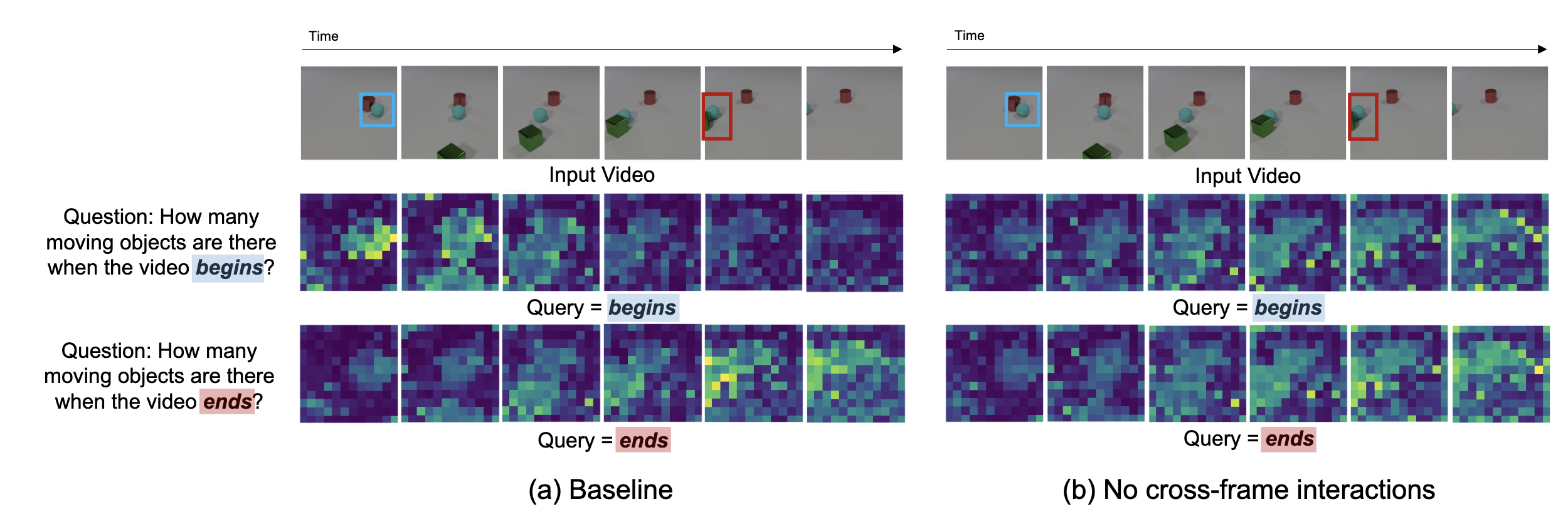
(a) Temporal reasoning begins with cross-frame interactions within video tokens at early-middle layers [green], followed by video-language integration into temporal keywords in the question [purple]. This information is conveyed to the last token at middle-late layers [orange], where answer generation occurs [yellow].
(b) These effective pathways are identified via Attention Knockout, which disconnects attention pairs and tracks the drop in probability of the final answer to quantify their impact.
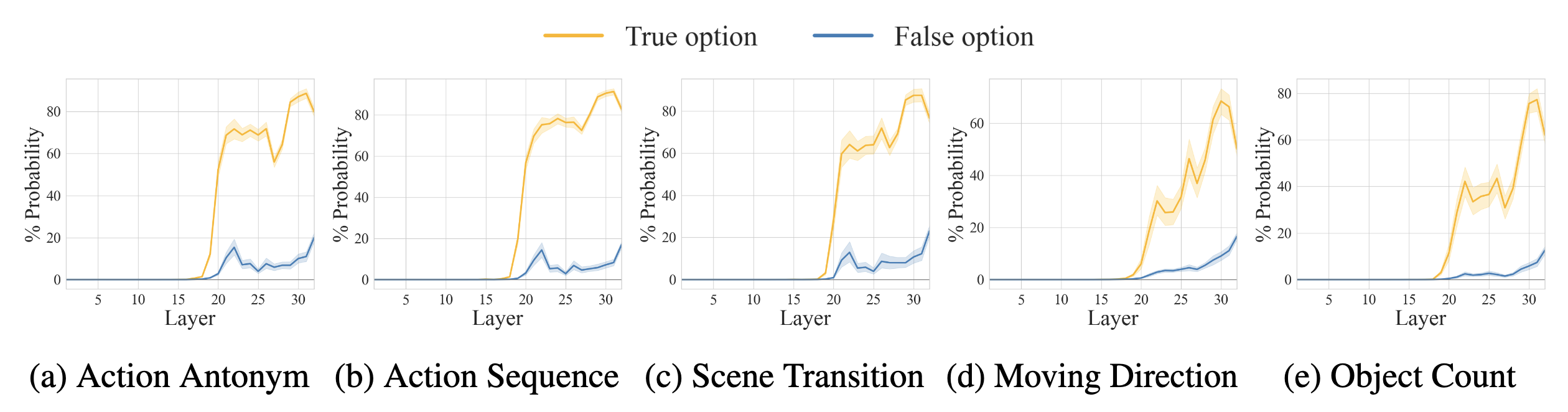
(c) Layer-wise answer probability rises immediately after video-language integration, indicating that the model is ready to predict correct answers after the middle layers.
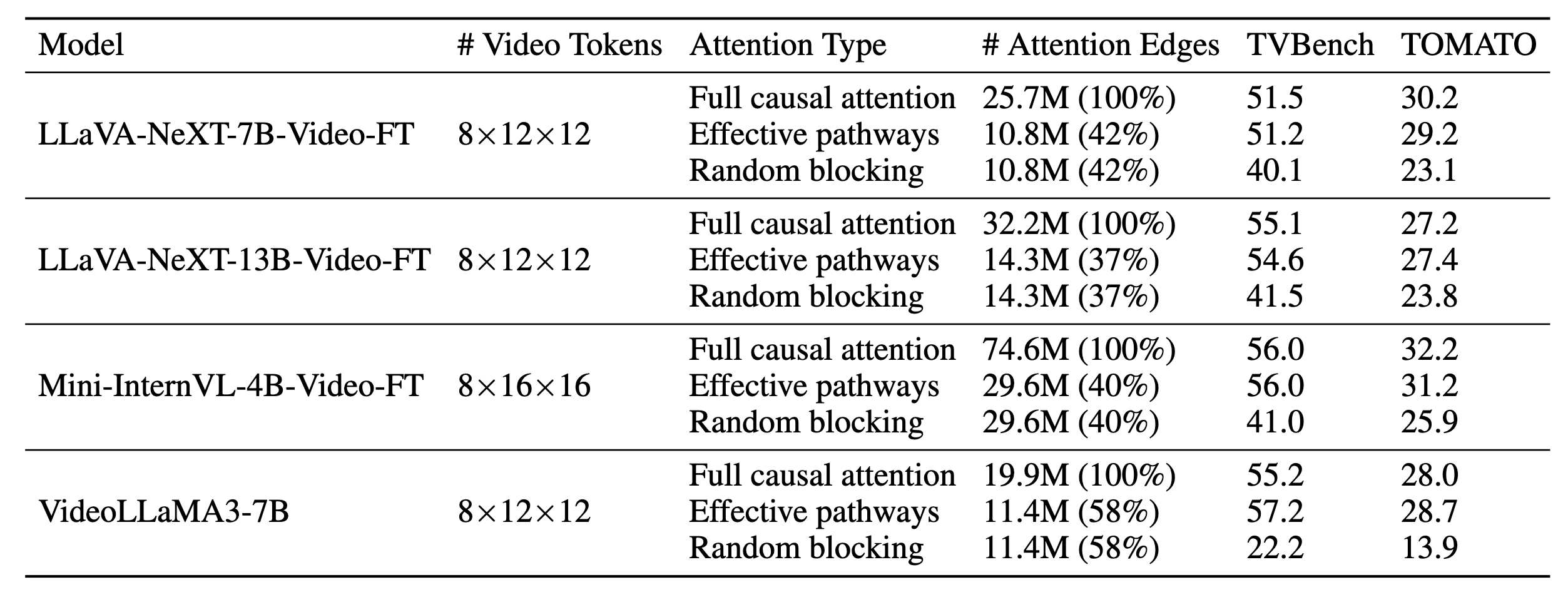
Based on our analysis, we show that VideoLLMs can retain their VideoQA performance by selecting effective information pathways while suppressing a substantial amount of attention edges, e.g., 58% in LLaVA-NeXT-7B-Video-FT.